


Hi there 👋
In this week's article, we will look into various Machine Learning testing tools.
The below tools are made to improve your model's accuracy, reliability and overall effectiveness.
Whether you are beginning your journey into ML or you are a seasoned expert, I hope you will find good use in the below repos.
Ready to check them out?

Shameless promotion: If you enjoy building ML and GenAI projects, how would you feel about getting rewarded for it? 🙃
To participate, sign up to Quira and check out Quests. The current prize pool is $2048; click on the image to learn more about it. 👇

Now that you have checked our Quests let's see how you can leverage the repos below to build an excellent ML/GenAI project. 🚀
Giskard-AI/giskard 🐢
A testing framework going from tabular to LLMs

Why should I consider this repo? Giskard can be seen as a health checkup for your models. It can scan many models, from simple tabular ones to advanced language models. Its flexibility to work in any environment and with any model makes it great for ensuring your models are fair, accurate, and ready for real-world applications. On a side note, I actually met up with their founder at a conference last year, and I was really impressed with their project!
Installation:pip install giskard -U
Getting started:
import giskard
# Replace this with your own data & model creation.
df = giskard.demo.titanic_df()
demo_data_processing_function, demo_sklearn_model = giskard.demo.titanic_pipeline()
# Wrap your Pandas DataFrame with Giskard.Dataset (test set, a golden dataset, etc.).
giskard_dataset = giskard.Dataset(
df=df, # A pandas.DataFrame that contains the raw data (before all the pre-processing steps) and the actual ground truth variable (target).
target="Survived", # Ground truth variable
name="Titanic dataset", # Optional
cat_columns=['Pclass', 'Sex', "SibSp", "Parch", "Embarked"] # List of categorical columns. Optional, but is a MUST if available. Inferred automatically if not.
)
# Wrap your model with Giskard.Model. Check the dedicated doc page: https://docs.giskard.ai/en/latest/guides/wrap_model/index.html
# you can use any tabular, text or LLM models (PyTorch, HuggingFace, LangChain, etc.),
# for classification, regression & text generation.
def prediction_function(df):
# The pre-processor can be a pipeline of one-hot encoding, imputer, scaler, etc.
preprocessed_df = demo_data_processing_function(df)
return demo_sklearn_model.predict_proba(preprocessed_df)
giskard_model = giskard.Model(
model=prediction_function, # A prediction function that encapsulates all the data pre-processing steps and that could be executed with the dataset used by the scan.
model_type="classification", # Either regression, classification or text_generation.
name="Titanic model", # Optional
classification_labels=demo_sklearn_model.classes_, # Their order MUST be identical to the prediction_function's output order
feature_names=['PassengerId', 'Pclass', 'Name', 'Sex', 'Age', 'SibSp', 'Parch', 'Fare', 'Embarked'], # Default: all columns of your dataset
)
scan_results = giskard.scan(giskard_model, giskard_dataset)
display(scan_results)
Here's an example of an output you could receive after testing your model. 👇
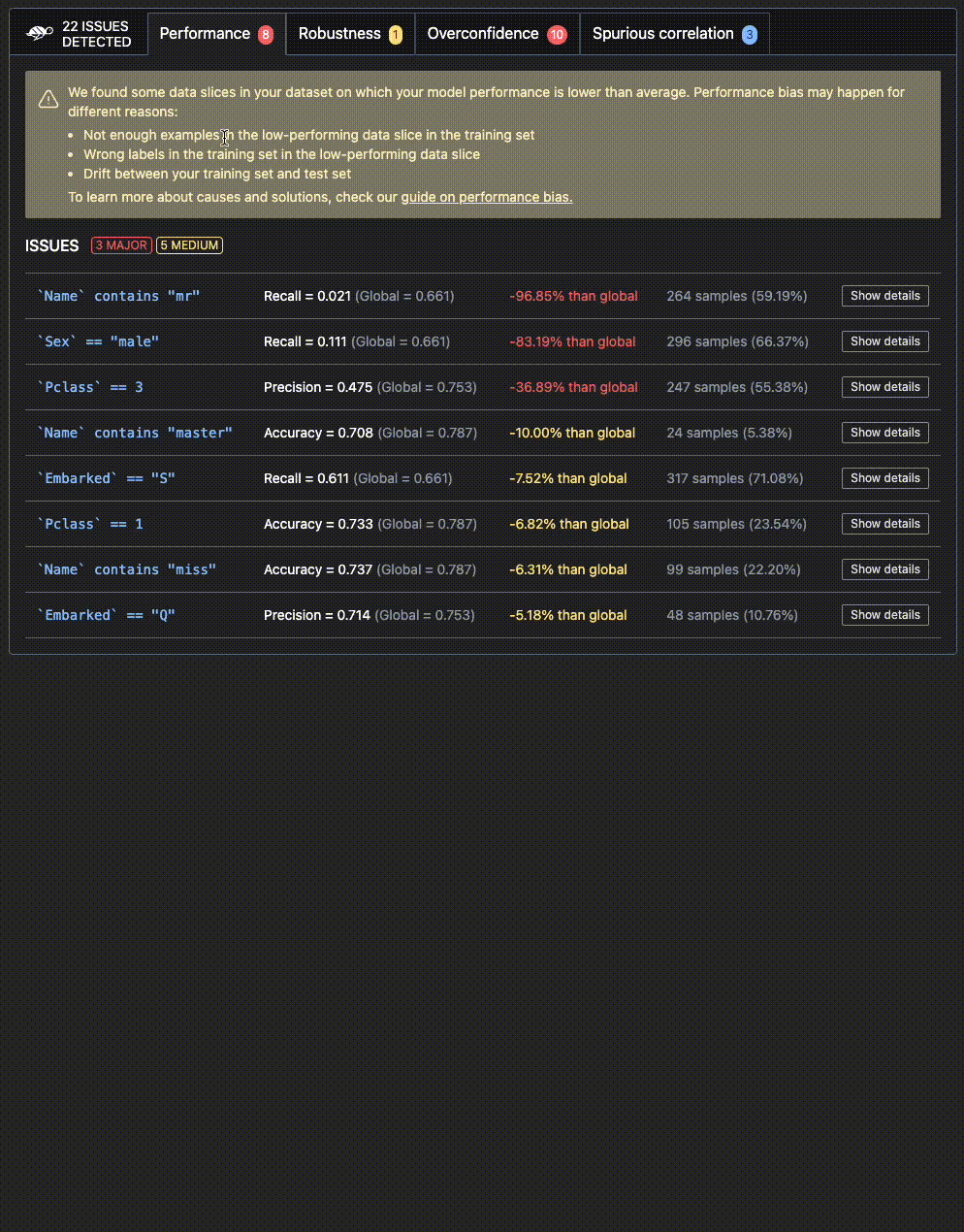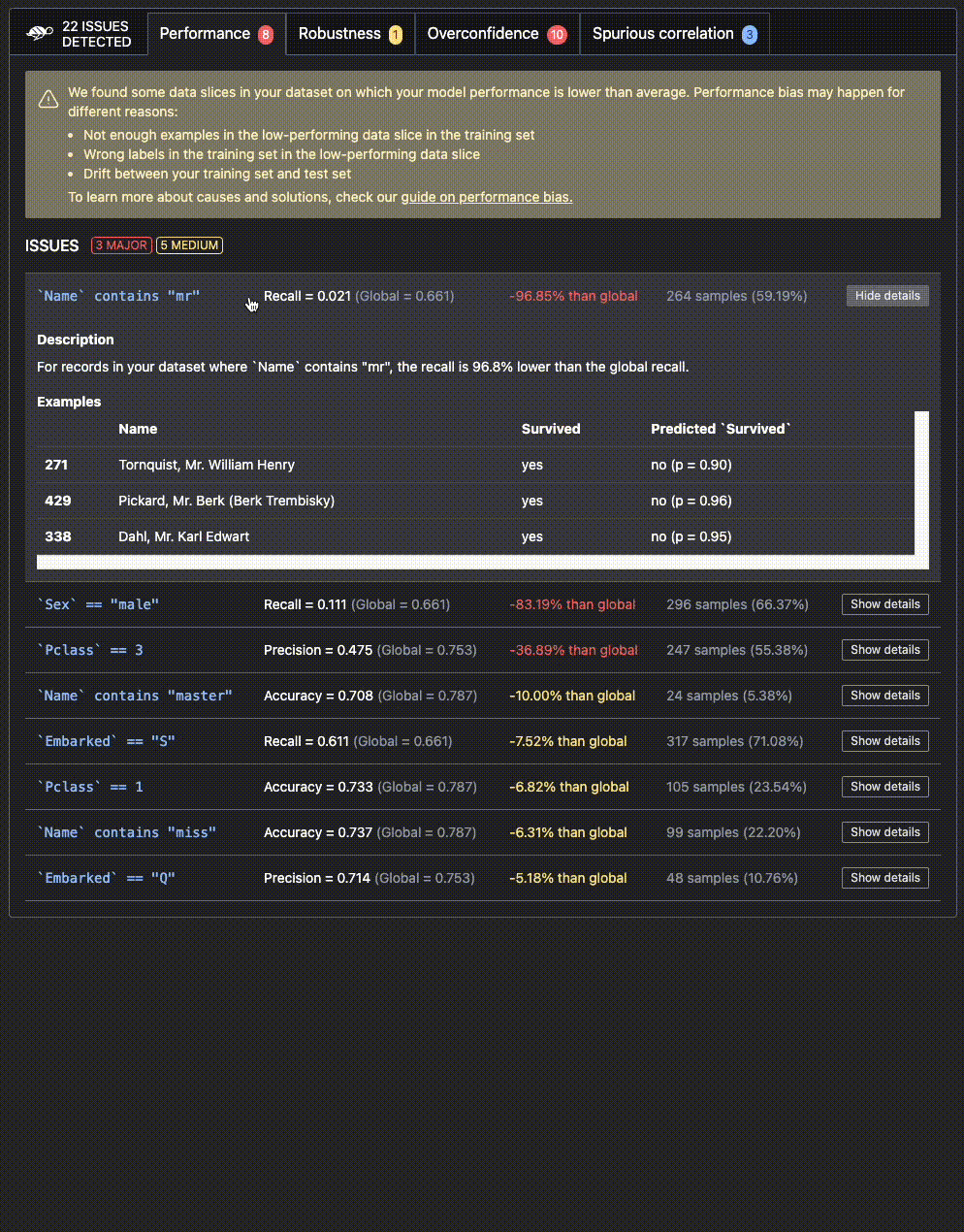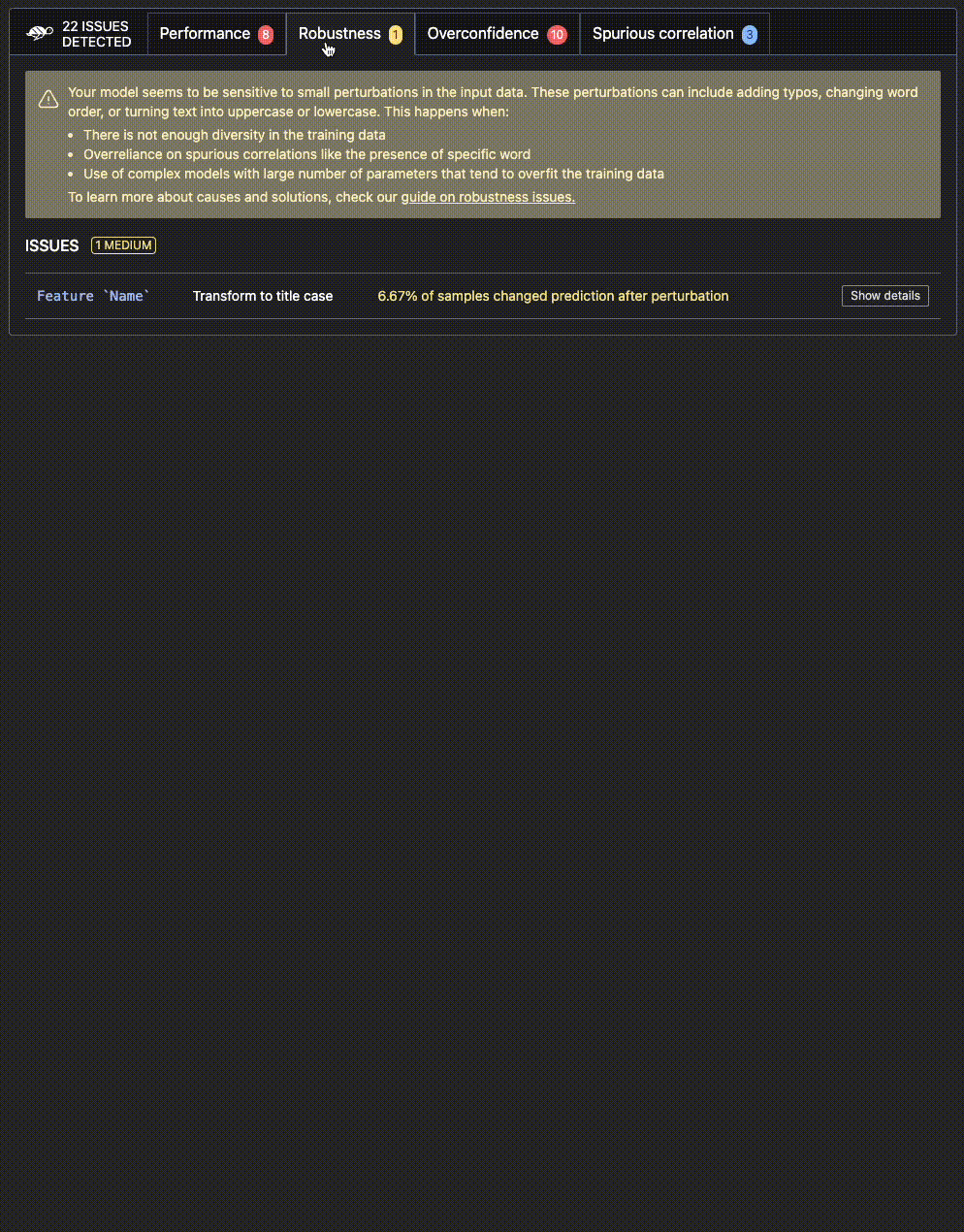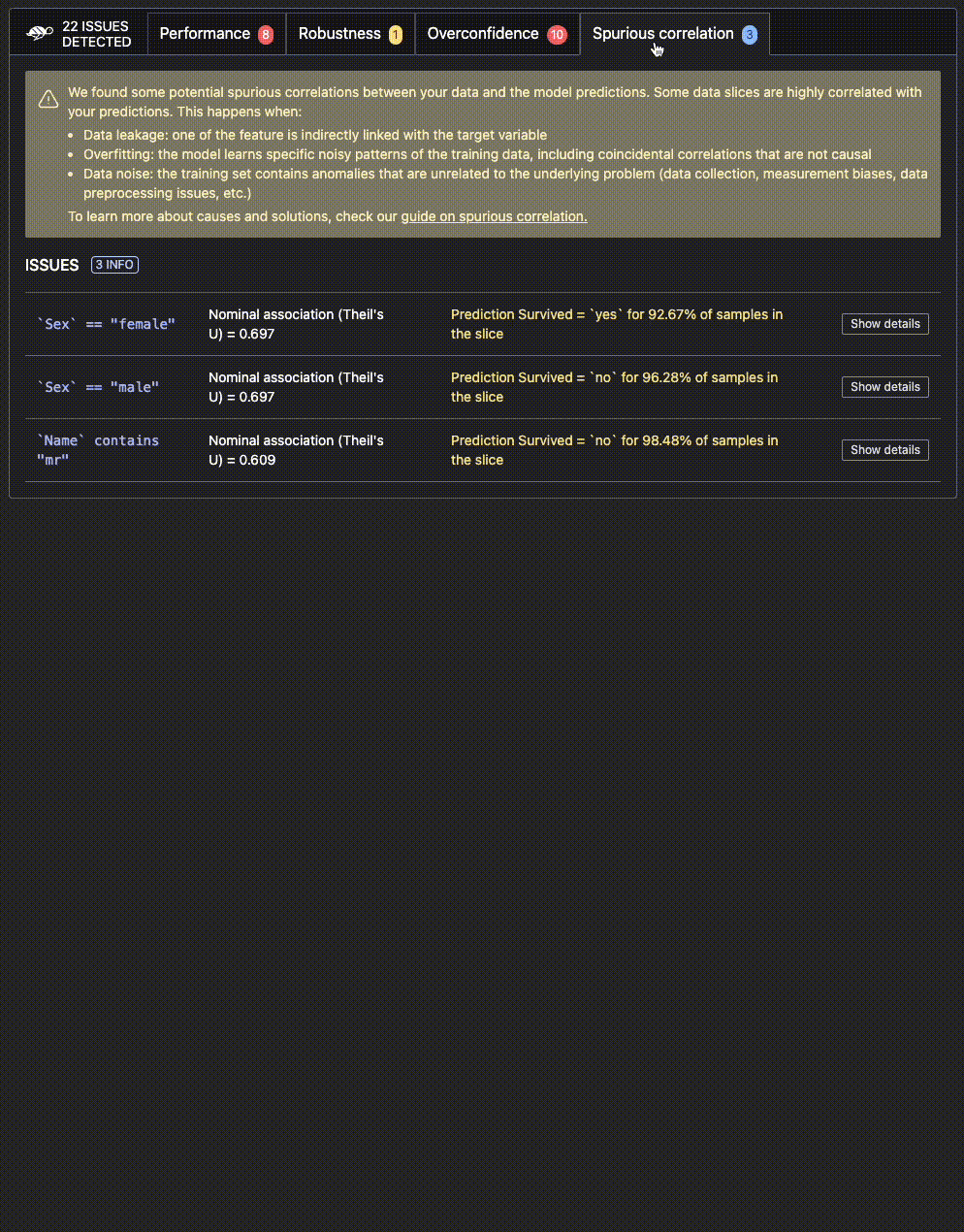
https://github.com/Giskard-AI/giskard
confident-ai/deepeval ✍️
The Evaluation Framework for LLMs
Why should I consider this repo? DeepEval is a tool for those working with LLMs. It offers a specialised, easy-to-use testing framework akin to Pytest but focused on LLMs. With its capability to run a variety of crucial metrics, it ensures thorough quality checks of LLM applications.
Installation:pip install -U deepeval
Getting started:
from deepeval import evaluate
from deepeval.metrics import HallucinationMetric
from deepeval.test_case import LLMTestCase
input = "What if these shoes don't fit?"
context = ["All customers are eligible for a 30 day full refund at no extra costs."]
# Replace this with the actual output from your LLM application
actual_output = "We offer a 30-day full refund at no extra costs."
hallucination_metric = HallucinationMetric(threshold=0.7)
test_case = LLMTestCase(
input=input,
actual_output=actual_output,
context=context
)
evaluate([test_case], [hallucination_metric])
Here's an example of an output you could receive after testing your model. 👇
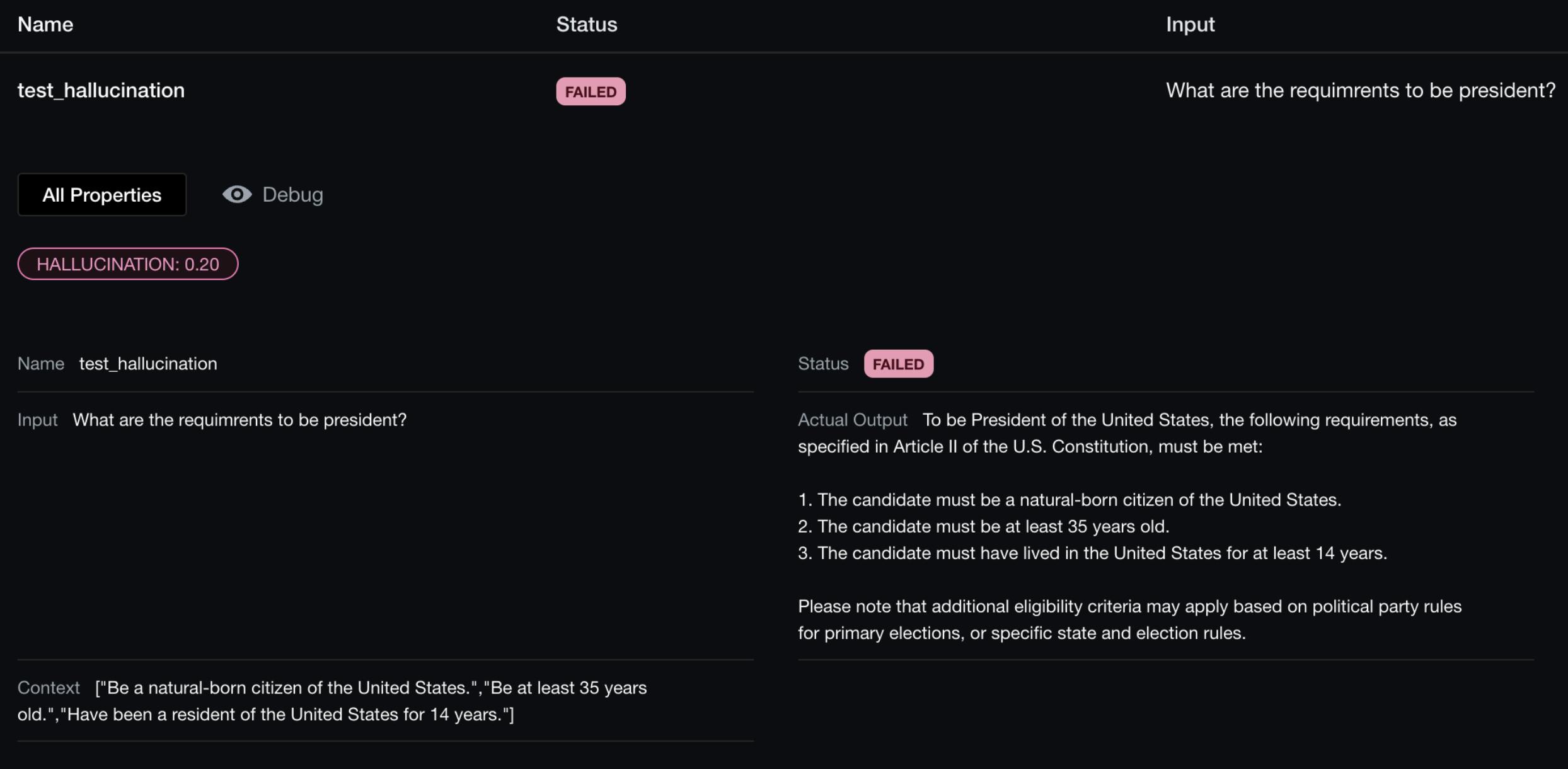
https://github.com/confident-ai/deepeval
promptfoo/promptfoo 🔎
Measure LLM quality and catch regressions
Why should I consider this repo? This tool should be used when you want to evaluate the output of different prompts with various LLMs. It's built to streamline evaluations with side-by-side comparisons, caching, and concurrency. You can leverage promptfoo for various known LLM providers (OpenAI, Gemini) and custom APIs.
Installation:npx promptfoo@latest init
Getting started:
import promptfoo from 'promptfoo';
const results = await promptfoo.evaluate({
prompts: ['Rephrase this in French: {{body}}', 'Rephrase this like a pirate: {{body}}'],
providers: ['openai:gpt-3.5-turbo'],
tests: [
{
vars: {
body: 'Hello world',
},
},
{
vars: {
body: "I'm hungry",
},
},
],
});
Here's an example of an output you could receive after testing your model. 👇
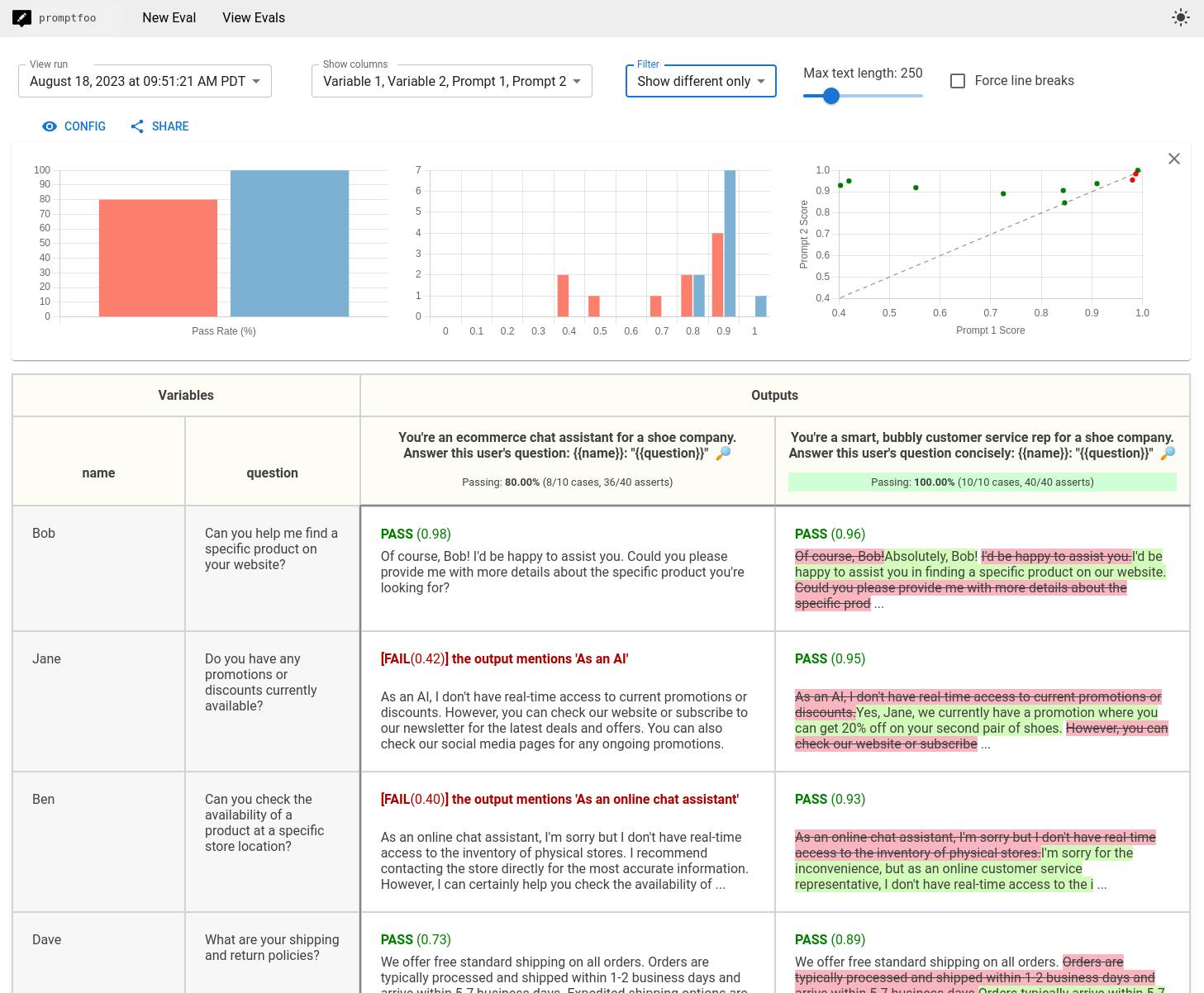
https://github.com/promptfoo/promptfoo
deepchecks/deepchecks ✅
ML testing for sklearn and pandas
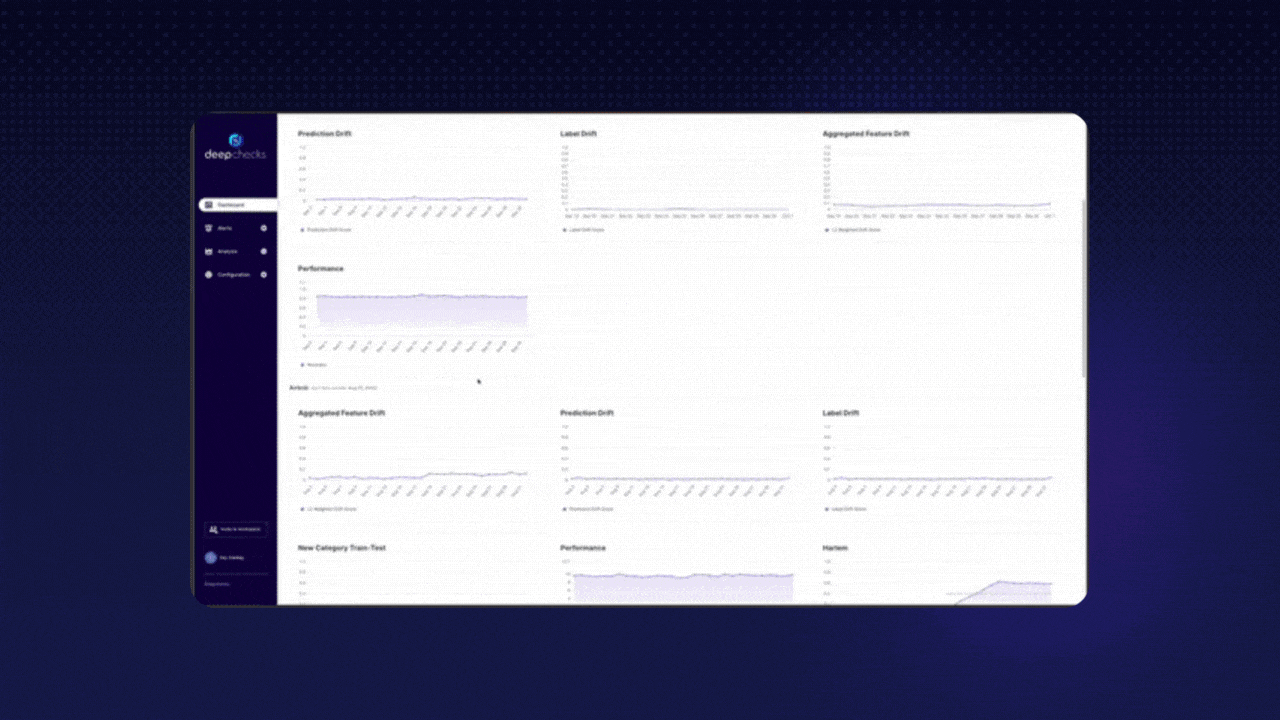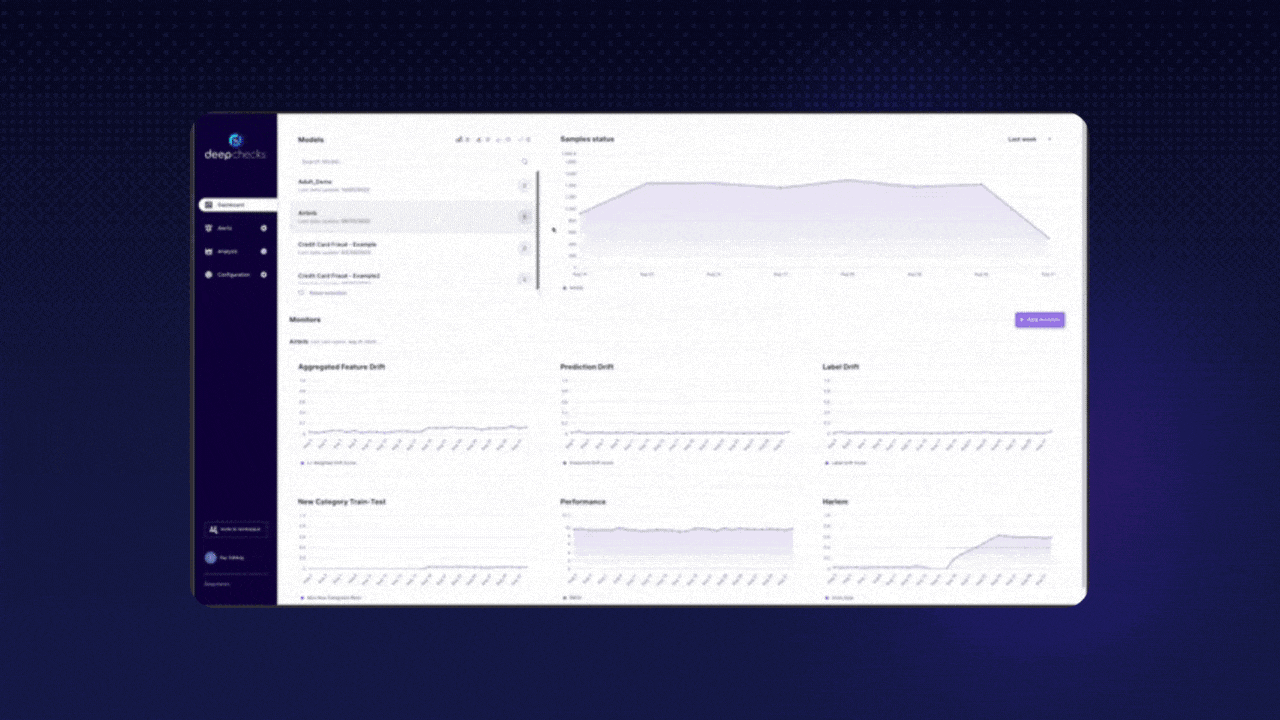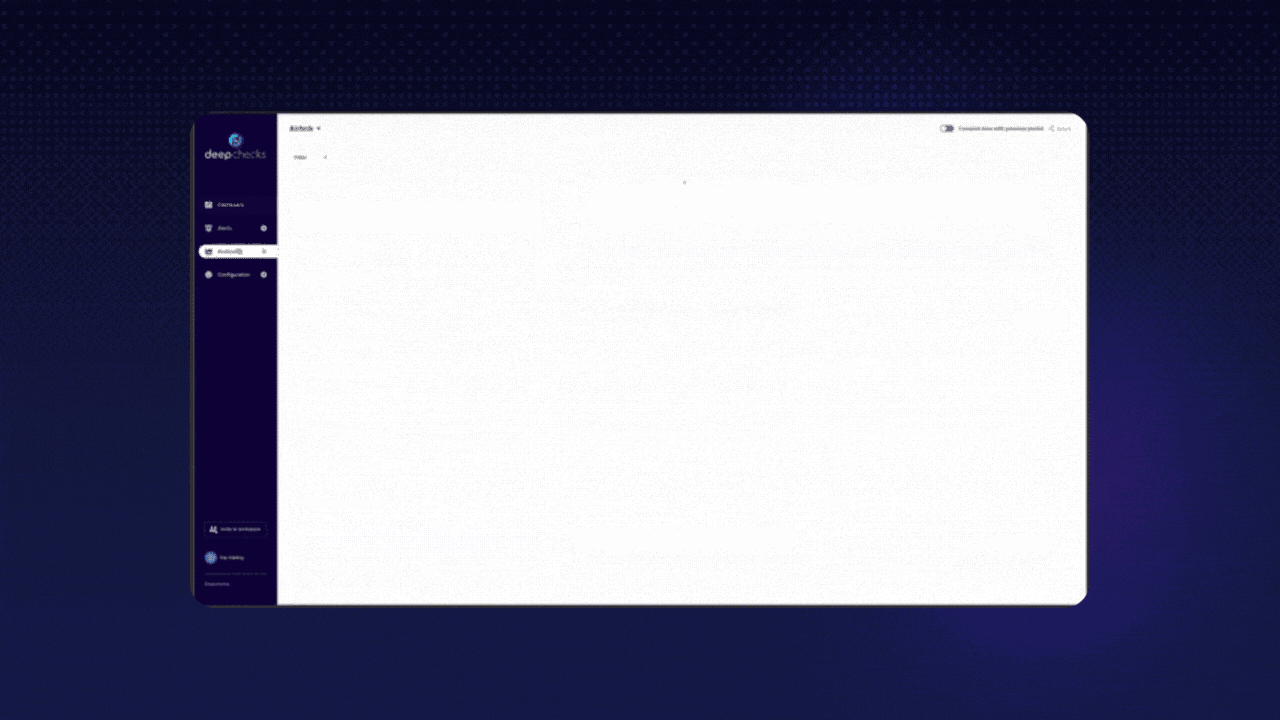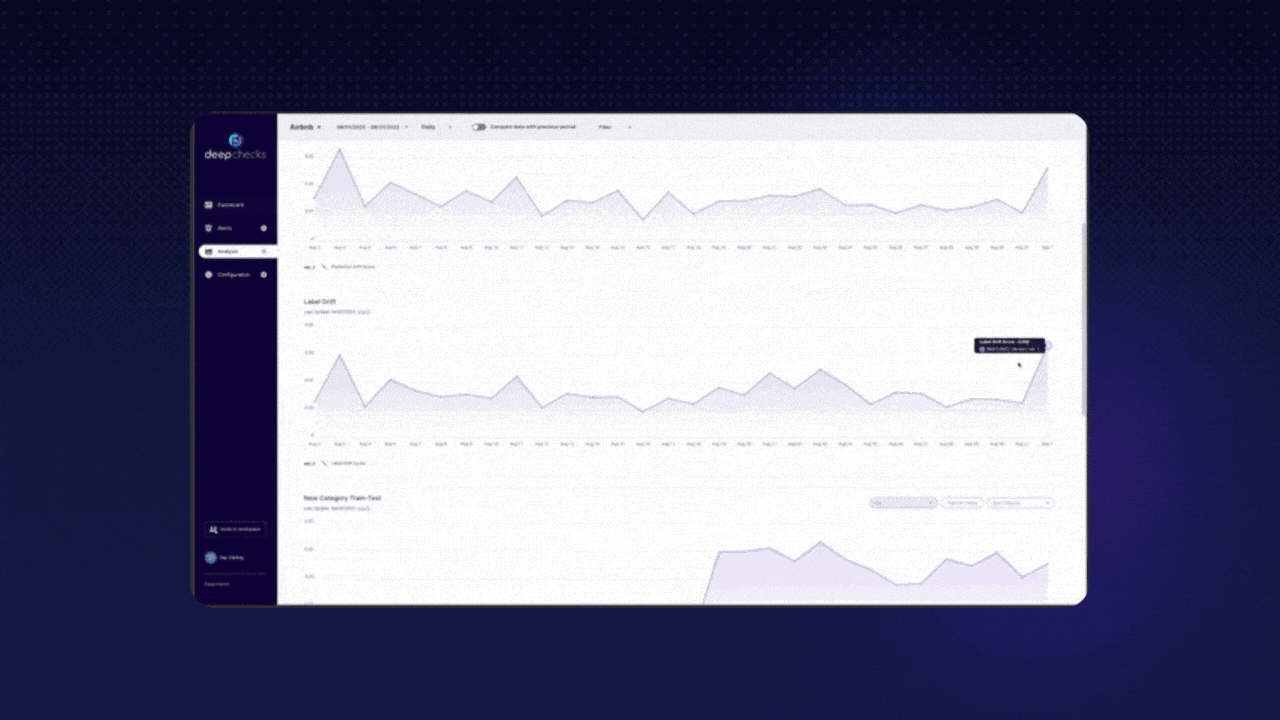
Why should I consider this repo? Deepchecks is a tool you can use at every stage, from research to production. It focuses on providing continuous validation, runs checks on different data types (Tabular, NLP, Vision), and integrates into your CI/CD workflows.
What is unique about this repo?
Installation:pip install deepchecks -U --user
Getting started:
from deepchecks.tabular.suites import model_evaluation
suite = model_evaluation()
suite_result = suite.run(train_dataset=train_dataset, test_dataset=test_dataset, model=model)
suite_result.save_as_html() # replace this with suite_result.show() or suite_result.show_in_window() to see results inline or in window
# or suite_result.results[0].value with the relevant check index to process the check result's values in python
Here's an example of an output you could receive after testing your model. 👇
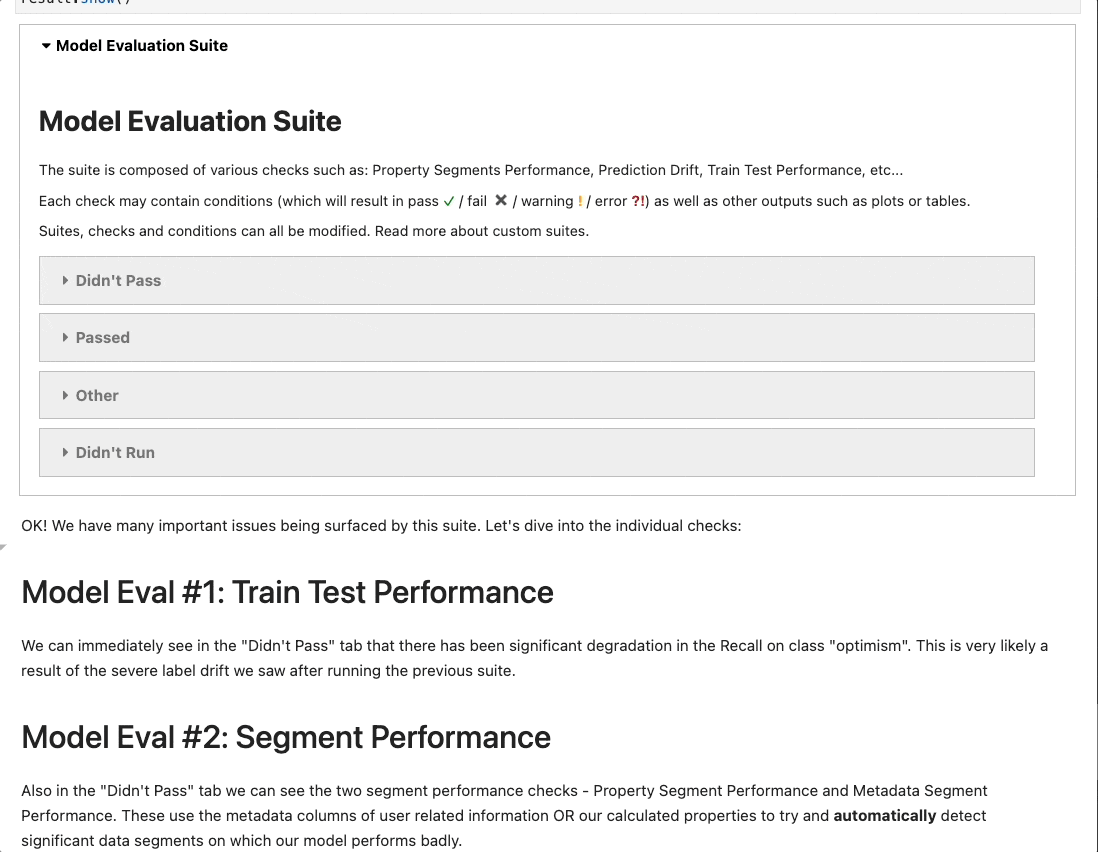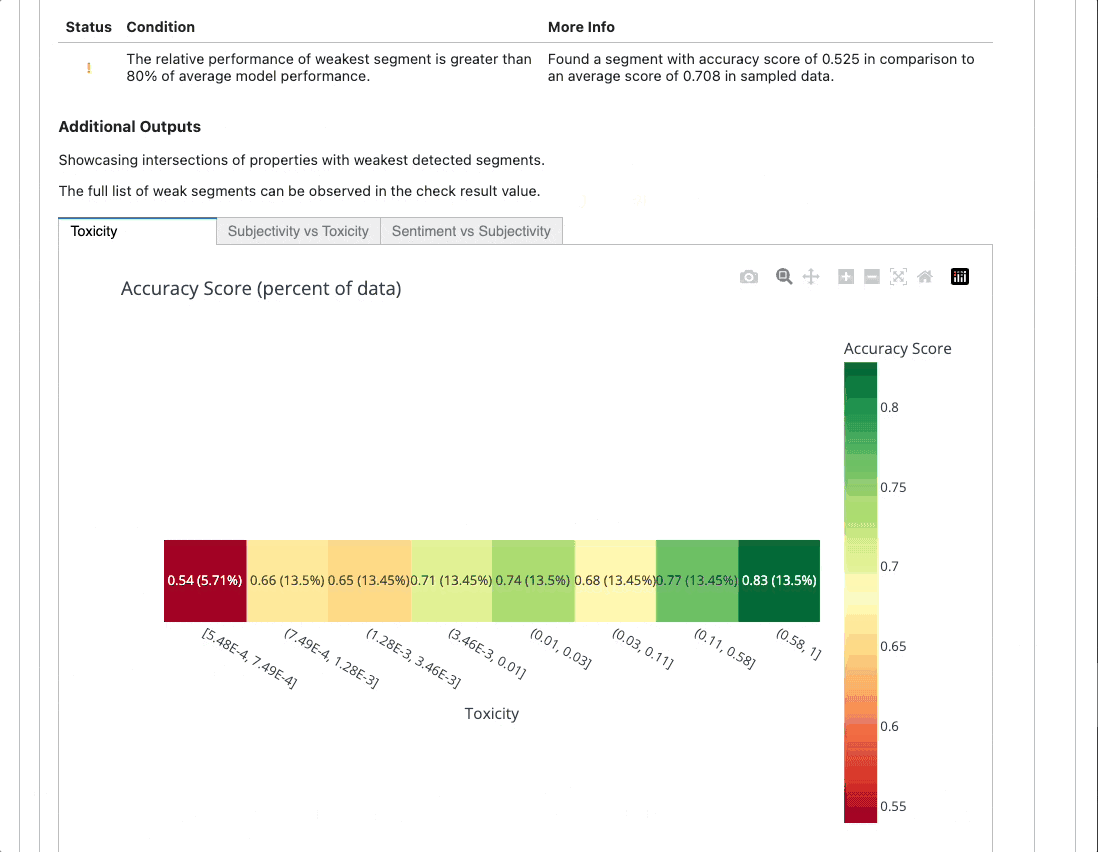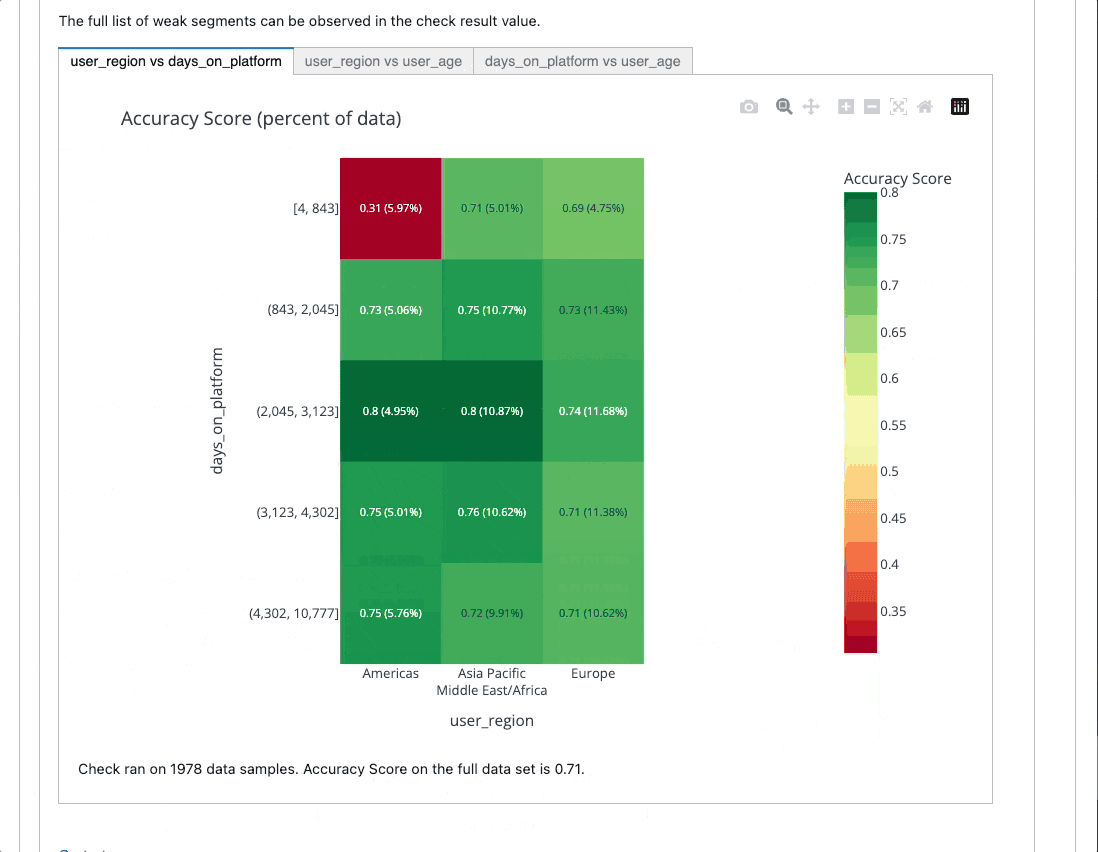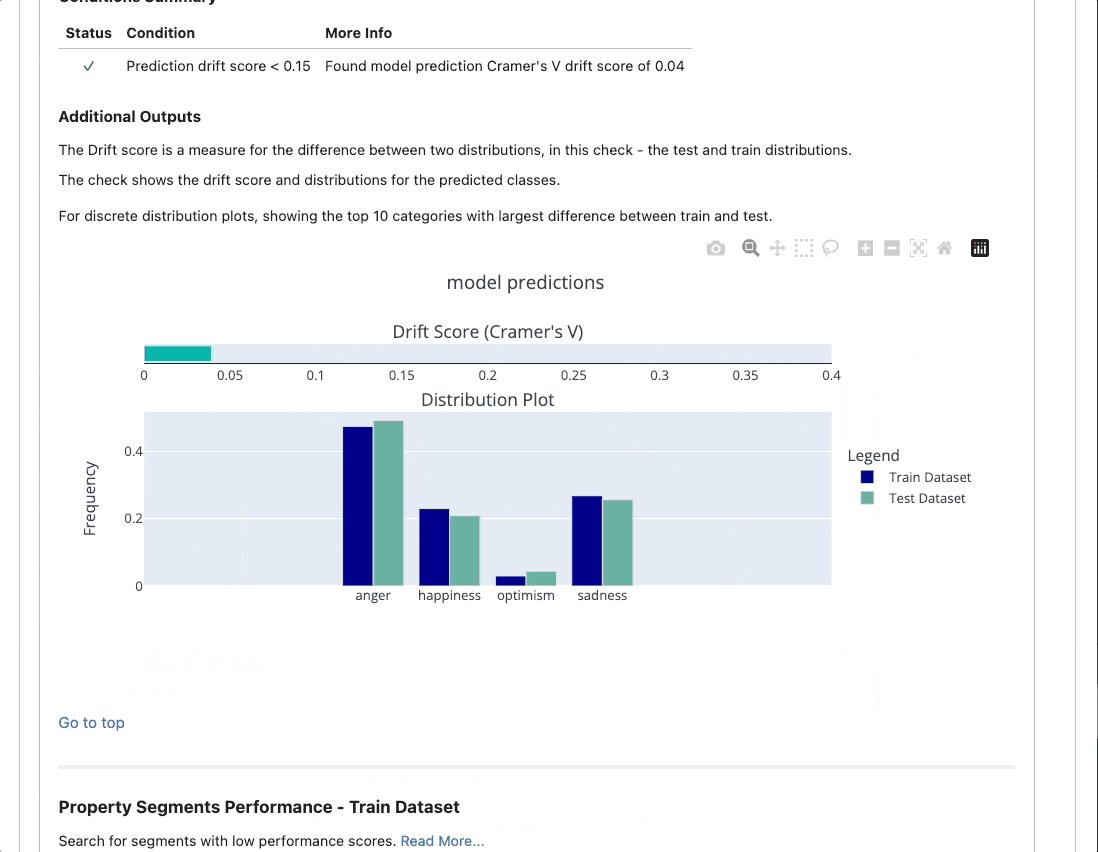
https://github.com/deepchecks/deepchecks
great-expectations/great_expectations 📊
Always know what to expect from your data
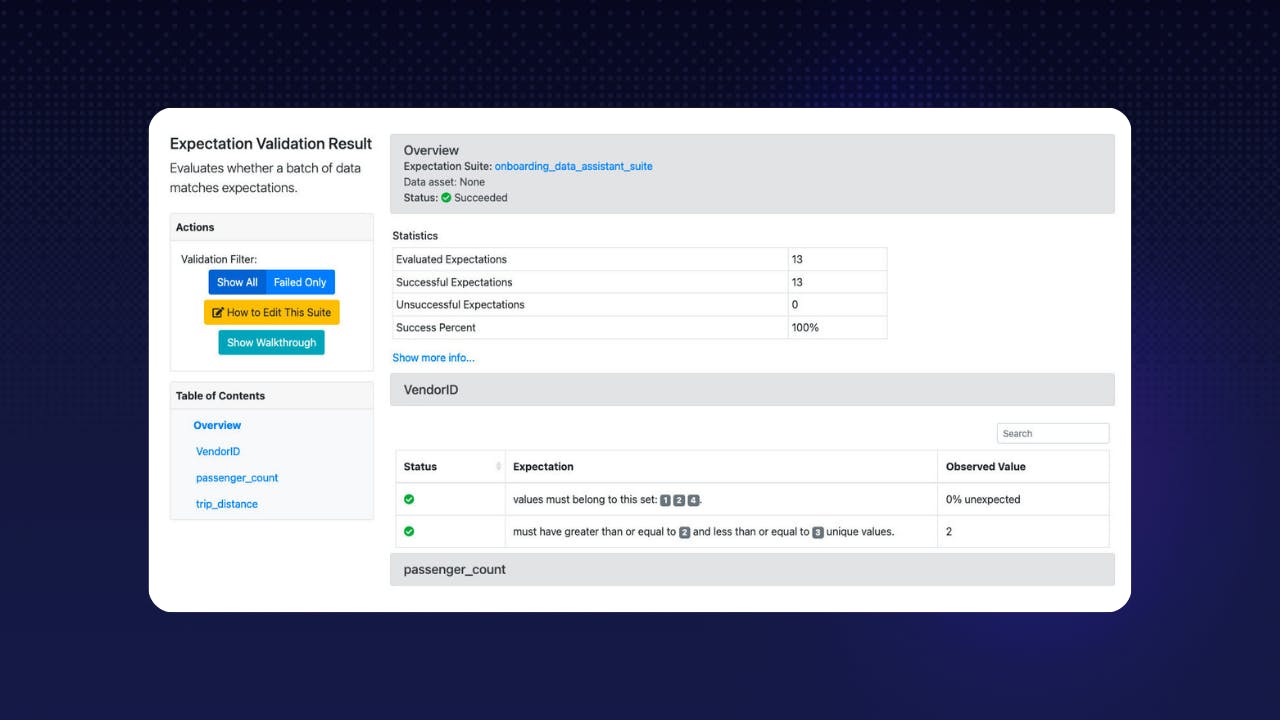
Why should I consider this repo? This tool is like a quality control expert for your data. Great Expectations is not a pipeline execution framework. Instead, it integrates seamlessly with DAG execution tools like Spark, Airflow, dbt , prefect, dagster , Kedro, Flyte, etc. It tests your data quality pipeline while these tools execute the pipelines.
Installation:pip install great_expectations
Getting started:
# It is recommended to deploy within a virtual environment
import great_expectations as gx
context = gx.get_context()
Depending on the tools and systems that you're already using, the setting up phase will be quite different.
This is why it is best to read up on their documentation (which I find really well-made)! 🤓
https://github.com/great-expectations/great_expectations
That's it for this one guys. 🌟
I hope these discoveries are valuable and will help you with your ML models! ⚒️
If you want to leverage these tools to build cool ML/GenAI projects and earn rewards, log into Quira and discover Quests! 💰

As usual, please consider supporting these projects by starring them. ⭐️
We are not affiliated with them.
We just think that great projects deserve great recognition.
See you next week,
Your Dev.to buddy 💚
Bap
If you want to join the self-proclaimed "coolest" server in open source 😝, you should join our discord server. We are here to help you on your journey in open source. 🫶
]